2021年8月24日~26日の3日間、オンラインにて開催された、日本最大のコンピュータエンターテインメント開発者向けのカンファレンス、“CEDEC2021”。本稿では、会期3日目の8月26日に行われたセッション“『ラブライブ!スクールアイドルフェスティバル ALL STARS』の機械学習によるコンテンツ制作支援 ~譜面作成ヘのディープラーニング活用~”の内容をリポートする。

本セッションでは、KLab KLabGames事業本部 エンジニアのオウ リンジィャン氏、同社開発推進部機械学習グループ エンジニアの高田敦史氏が登壇。スマートフォン向けリズムゲーム『ラブライブ!スクールアイドルフェスティバル ALL STARS』(以下、『スクスタ』)での機械学習による譜面作成支援の事例が紹介された。


『スクスタ』には、音楽に合わせてノーツをタップするリズムアクションパート(ライブパート)が存在する。譜面とは、この際に流れてくるノーツのタイミングや種類を設定するもののこと。
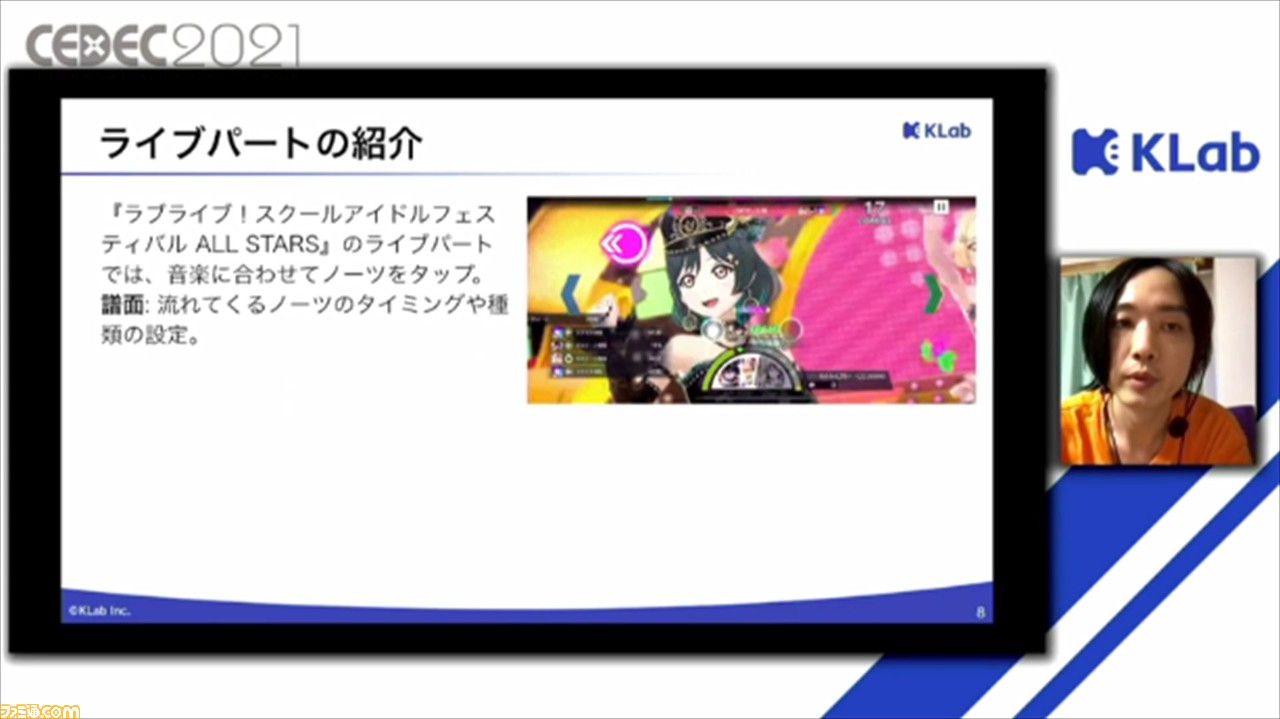
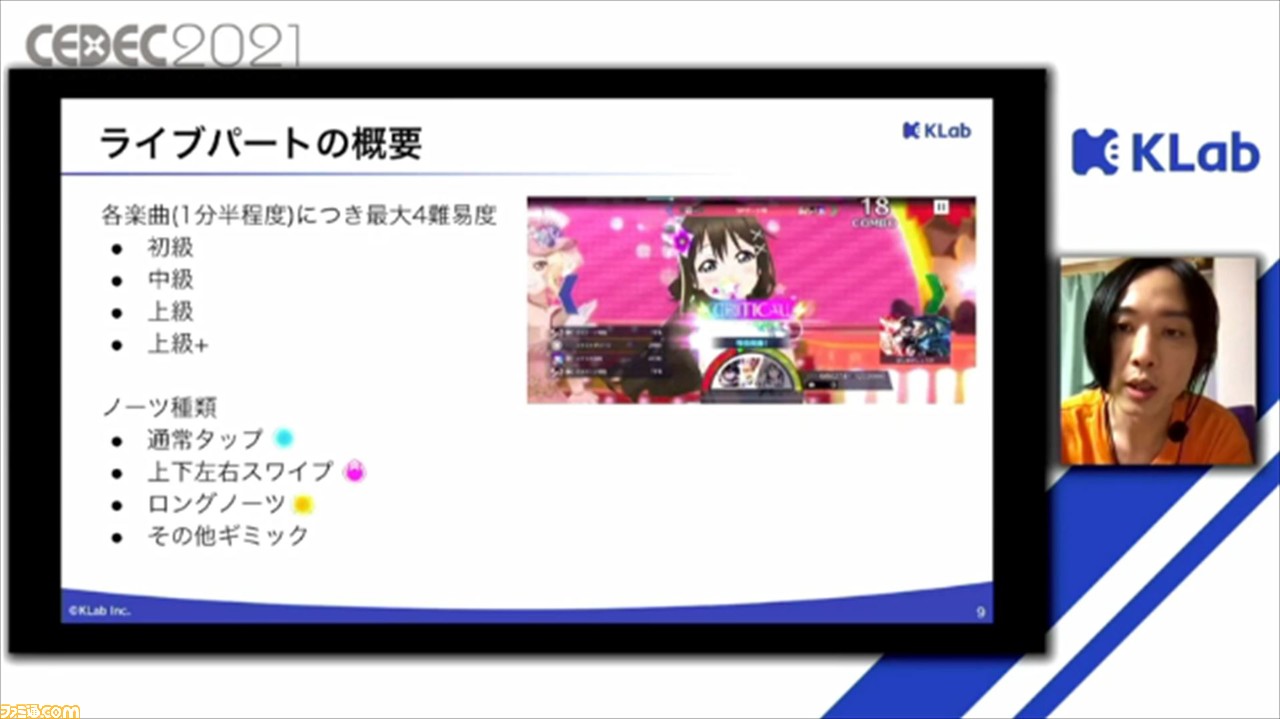
各楽曲の長さは、1分半~2分程度。難易度は、初級、中級、上級、上級+があり、難易度が上がるにつれてノーツの数も増加する。ノーツには、通常のタップのほか、上下左右のスライド、長押しのロングノーツ、演出に絡むギミックノーツがある。
人間が制作する場合の譜面制作のワークフローでは、ゲームの音楽などを担当するサウンドチームがMIDIファイル形式で、ベースとなるデータを作成。そこに企画チームが演出などを追加することで完成する。
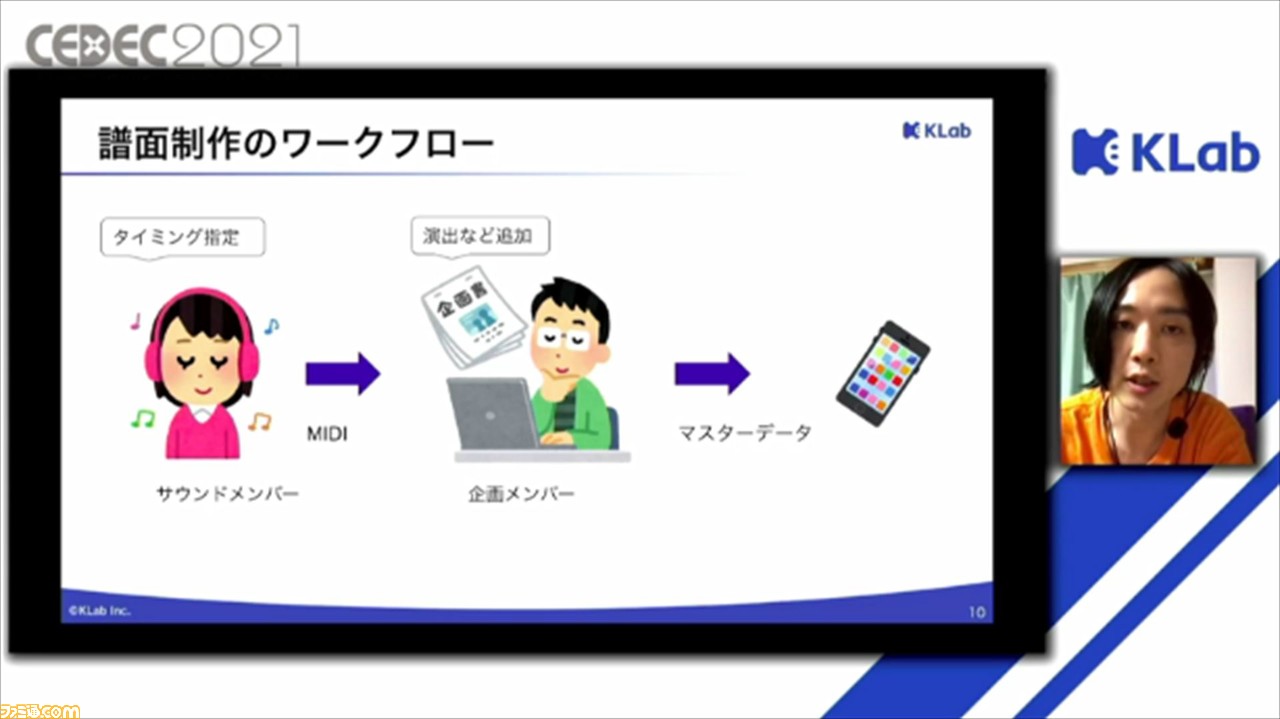
ここで大変なのが、MIDIファイルの作成。音楽に合わせてノーツを置きたい場所に手作業で指定しながら作成していくので、どうしても時間がかかってしまうという。1曲あたり40時間程度必要となるそうだ。

譜面制作支援ツールが導入された経緯としては、昨年2020年に新曲の追加のベースが倍増したことがきっかけだそう。
当初の想定では、年に24曲を追加していく予定だったが、年に60曲が実装したいという要望があり、現状の体制では対応が難しい状況だったという。
そのため、機械学習チームも巻き込んで、制作効率化のためのツール開発をスタートさせたそうだ。

本プロジェクトで実現したいことは、全自動で譜面を作るのではなく、人間による調整を加えることを前提に、ベースとなるデータを機械学習で作成し、単純作業の自動化を図ることだという。
これには、『スクスタ』ではダンスに合わせてスワイプの向きを変えたり、歌詞に合わせてノーツの種類を変えたりなど、演出上のこだわりがたくさんあるため、それらすべてを自動化するのが難しいという背景もあるそうだ。
ほかにも、近年の機械学習によるコンテンツの自動生成の領域が注目されていることも、要因のひとつとしてあるという。しかし、機械学習で作られるコンテンツの質も上がってはいるが、実用化に至るケースが少ないのだそう。
一方で、リズムアクションゲームにおける譜面制作のような、自由度の低いコンテンツなら実用化可能だと考え、本ツールを導入したことで、作業時間の50%をカットすることに成功したそうだ。

ここからは、ツールの使いかたについて解説。まずは、専用アカウントにログインし、楽曲をアップロード。このとき、楽曲のBPMの指定も可能。BPMを指定することで、譜面制作の精度が上がるとのこと。
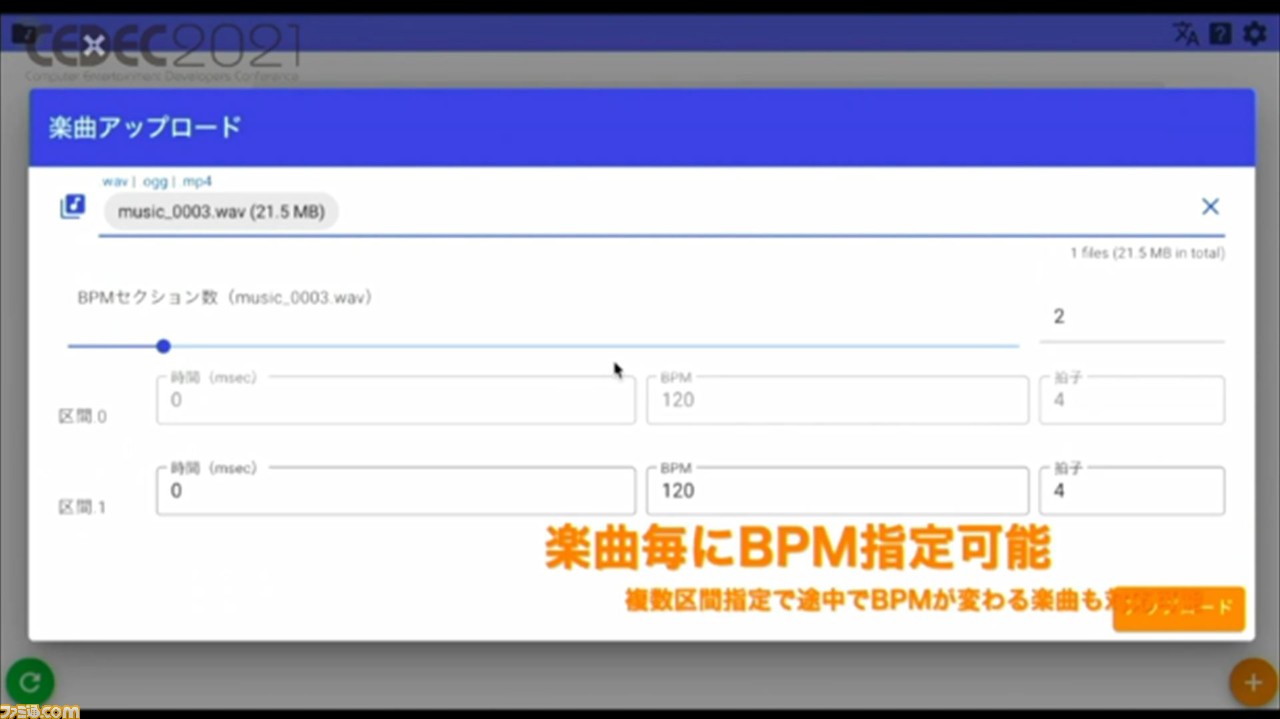
アップロード後は、楽曲から譜面を生成するためのデータを取得するための前処理が行われる。これにより、譜面制作の処理コストが抑えられるという。
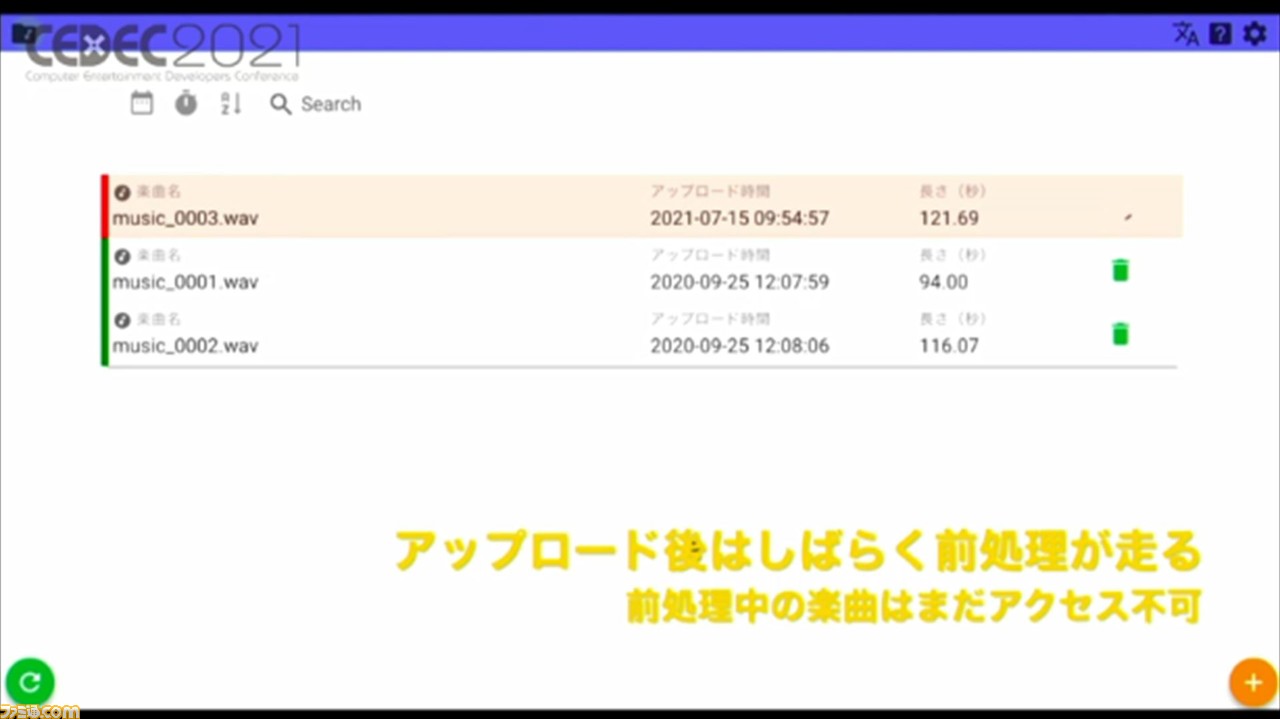
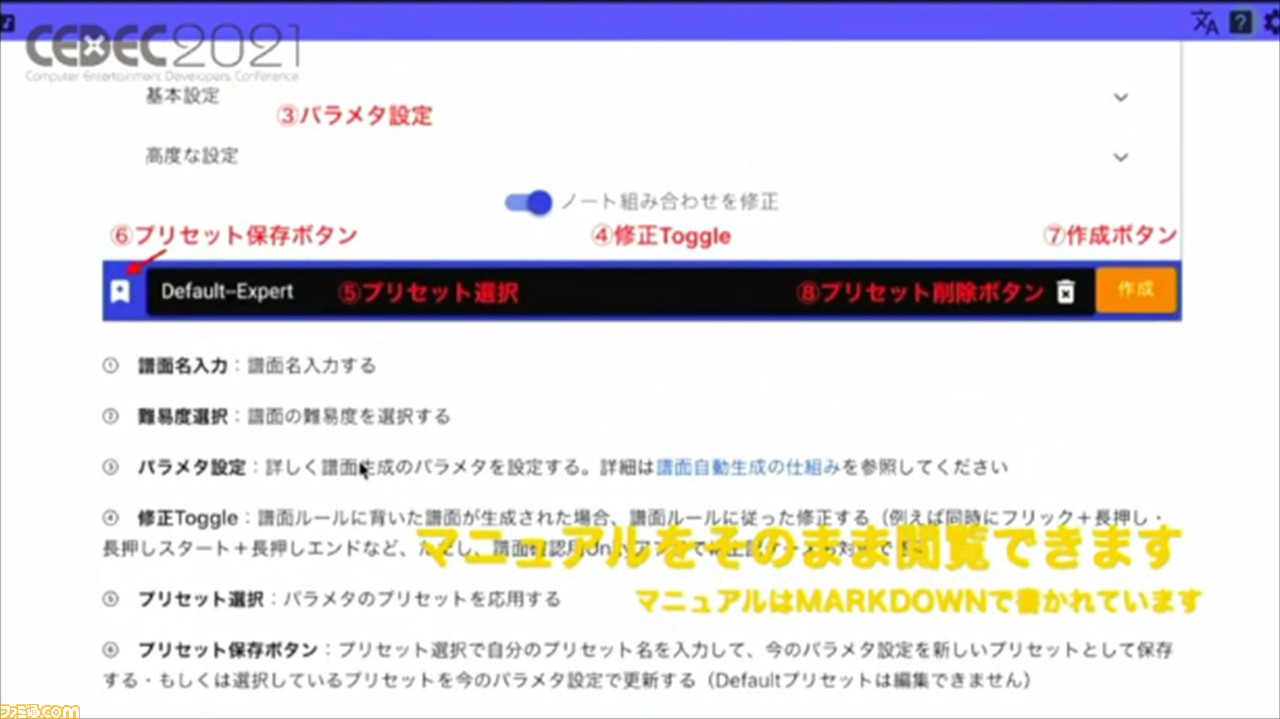
前処理が終わると、楽曲ごとの譜面の管理画面に移行。ここでは、複数のモデルの譜面が作成できる。譜面の各種パラメータも入力可能で、エラー検知機能やツールチップもあるので、マニュアルがなくても簡単に作業できるそうだ。
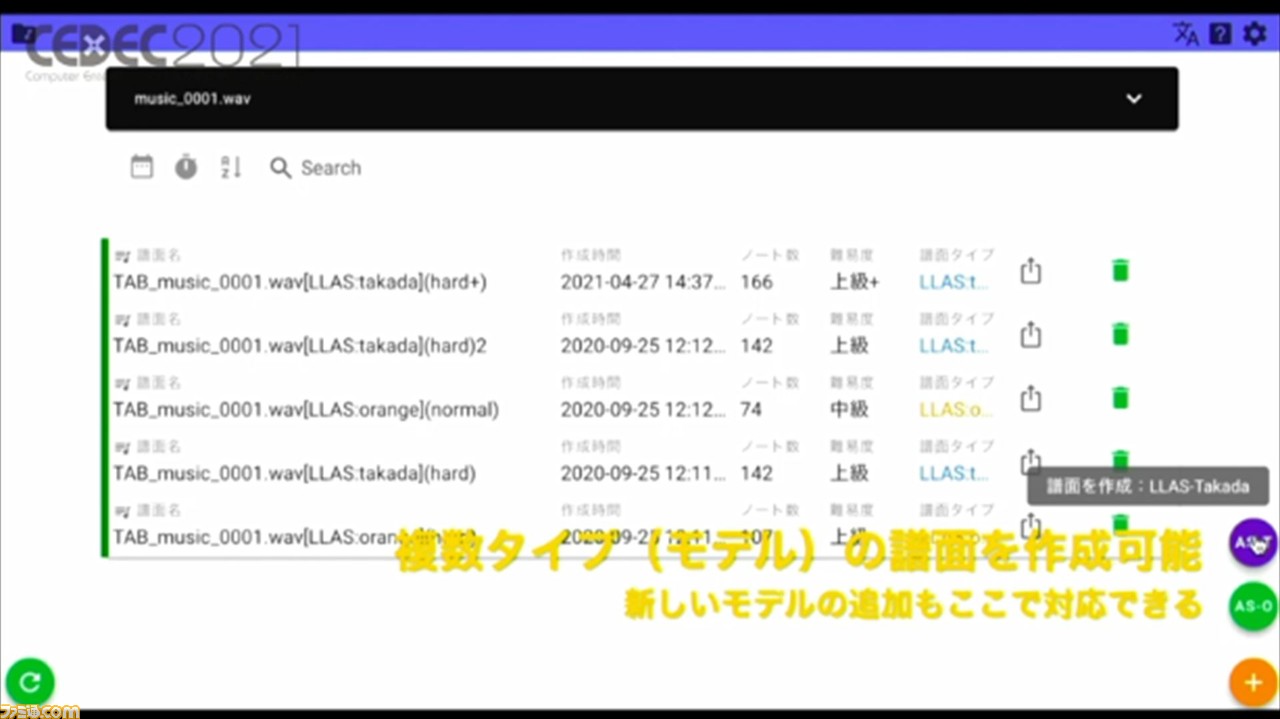
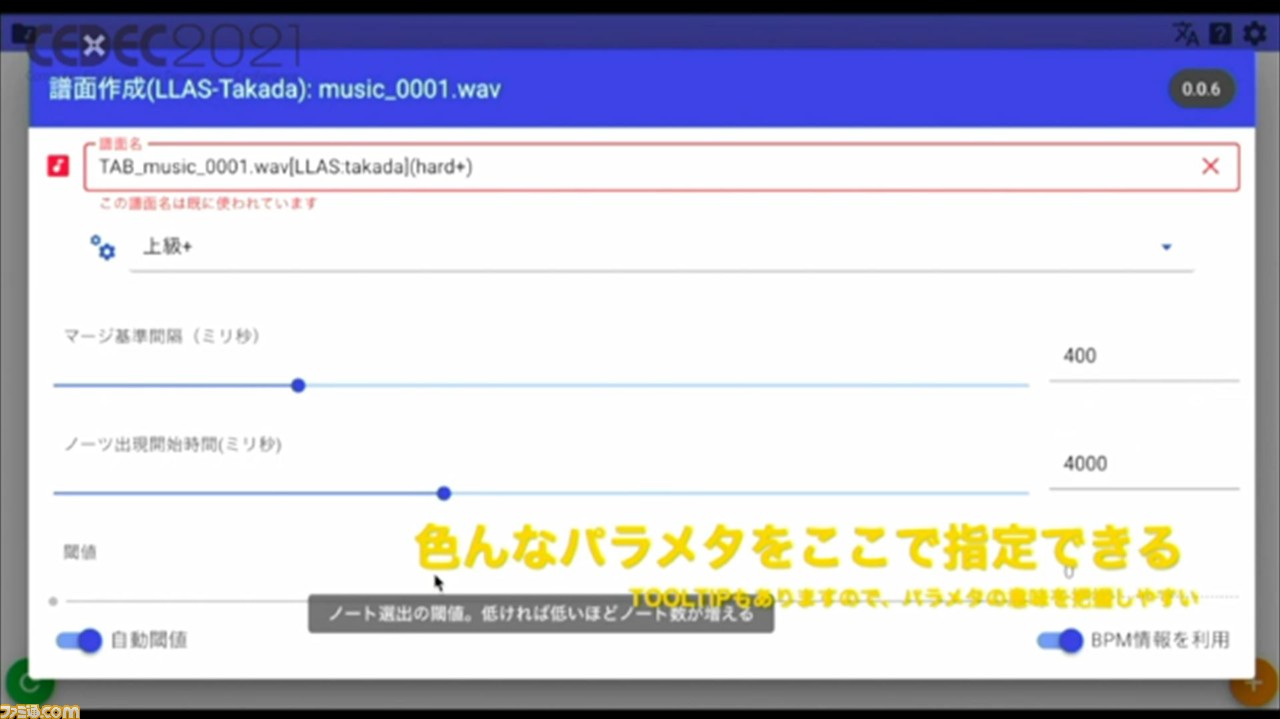
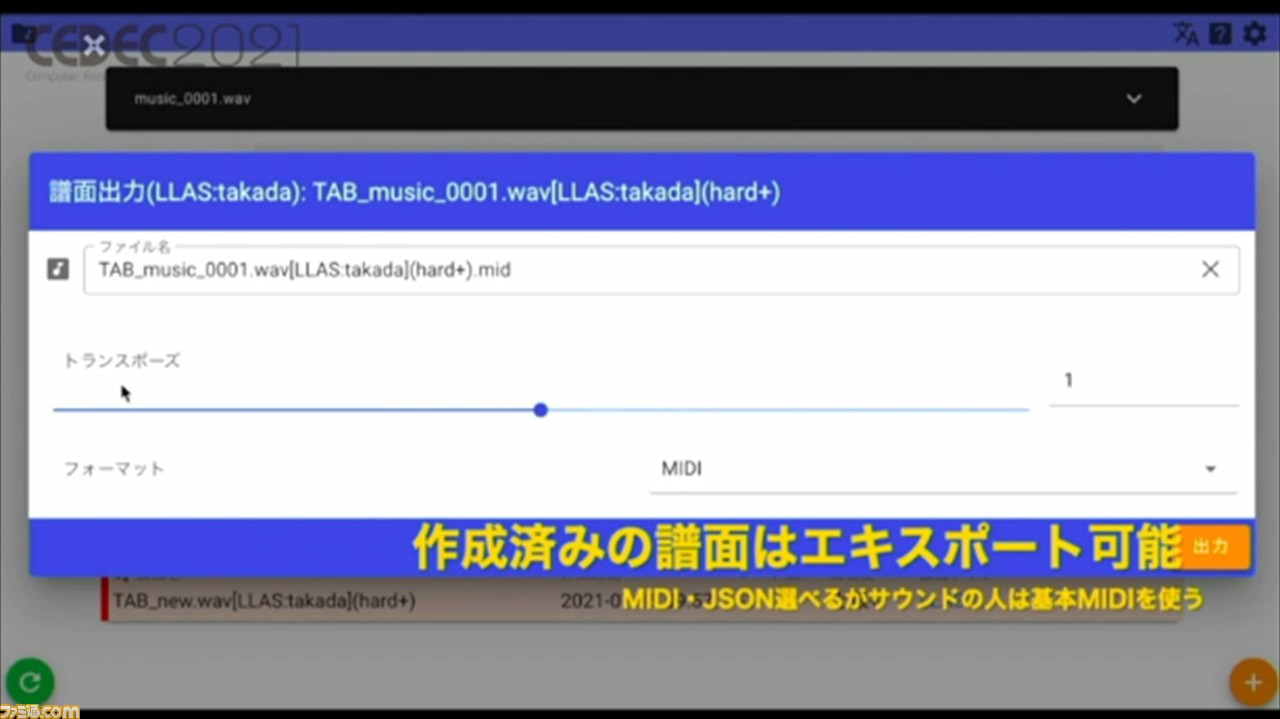
完成した譜面は、エキスポートボタンでMIDIかJSON形式で出力できる。処理が完了すると、Slackへの通知を送る機能や、ツール内からマニュアルを閲覧できる機能も搭載されている。ほかにも、作成した譜面を確認できるアプリを、ゲームエンジン“Unity”で開発し、実装しているそうだ。
続いては、譜面自動化のWEBサービスについて、システム構成、使いやすくするためのポイント、少人数で効率的に開発を進めるポイントの3点から解説された。

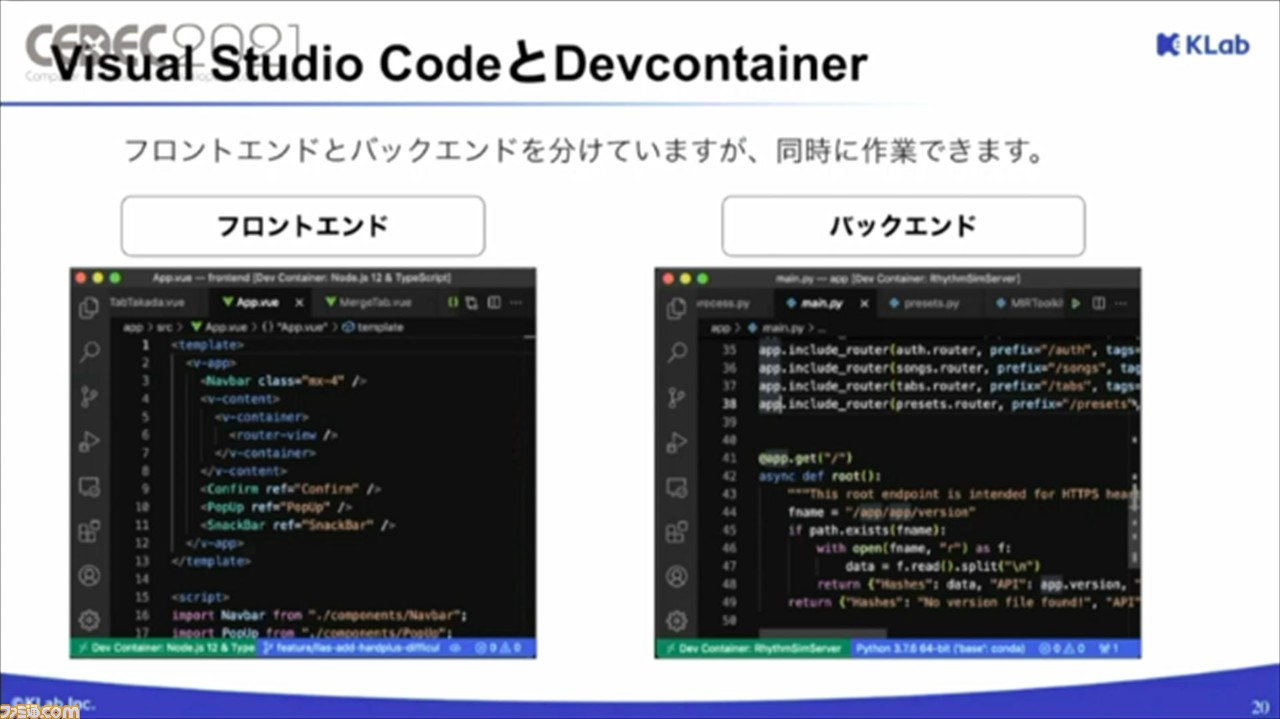
まずは、システム構成について。譜面はWEBアプリで生成し、サウンドチームと企画チームの編集を経てゲームに実装される。WEBアプリであれば、非エンジニアでも使いやすく、ブラウザのみでアクセスできるため、環境依存もなく、不特定多数のユーザーに共有しやすい、という利点がある。

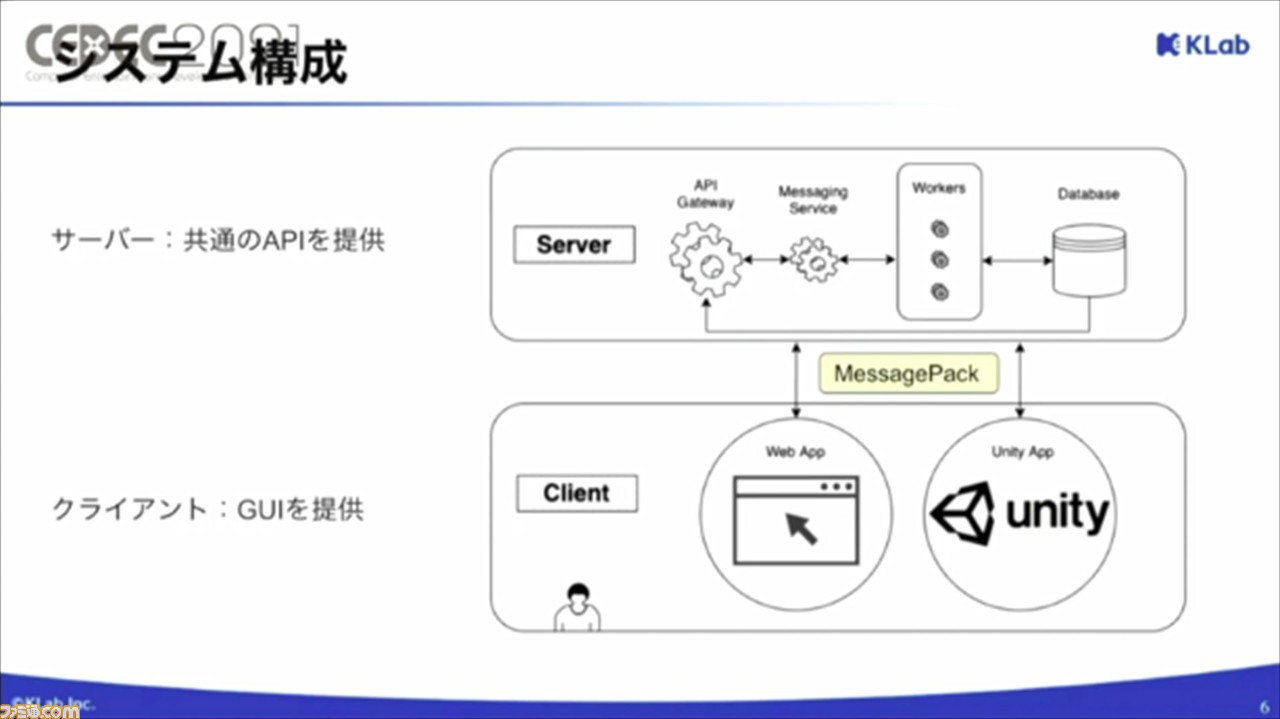
実際のシステム構成は、図とともに説明された。サーバーとクライアントでわけられており、クライアントはGUI(グラフィカルユーザインタフェース)を、サーバーはAPIを提供。両者のやり取りは、メッセージパックで行われる。
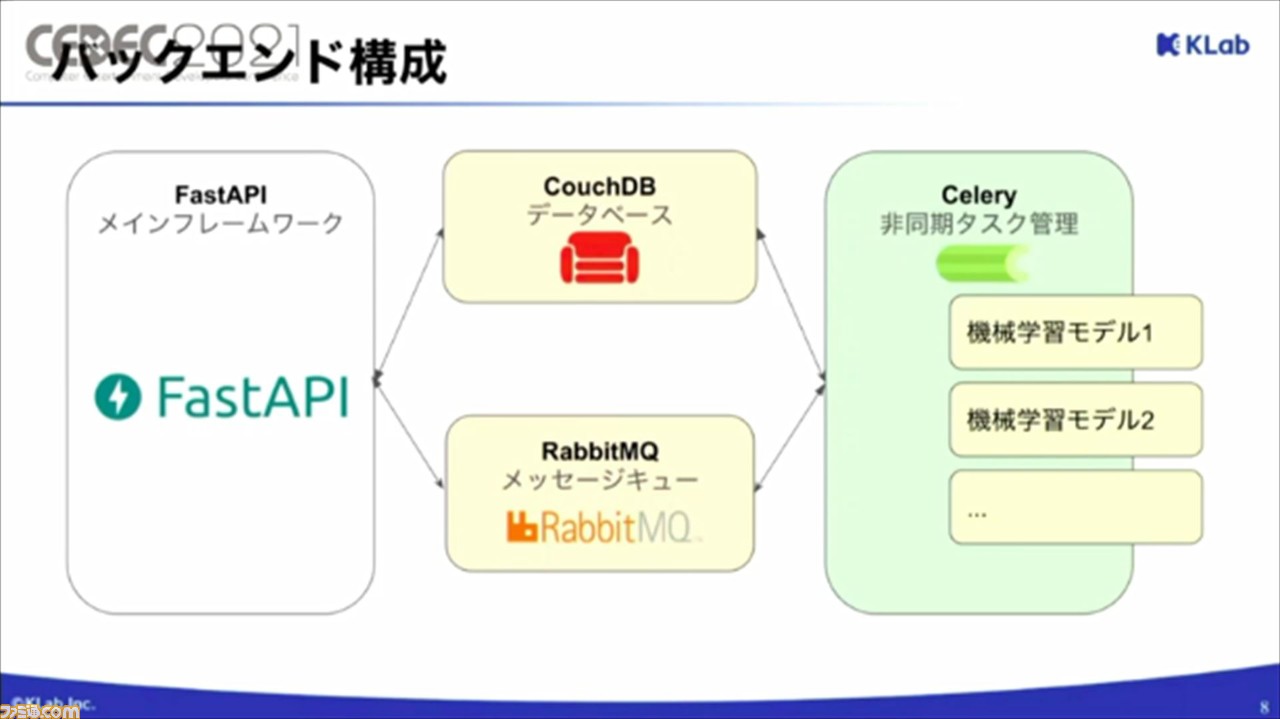
サーバー側となるバックエンドの構成は、FastAPIをメインフレームワークとして採用。データベースはCouchDB、タスク管理はCelery、メッセージキューはRabbitMQで構成されている。
一方、クライアント側となるフロントエンドの構成は、Vue.jsをメインフレームワークとして採用し、いくつかのプラグインを加えることで構成されている。
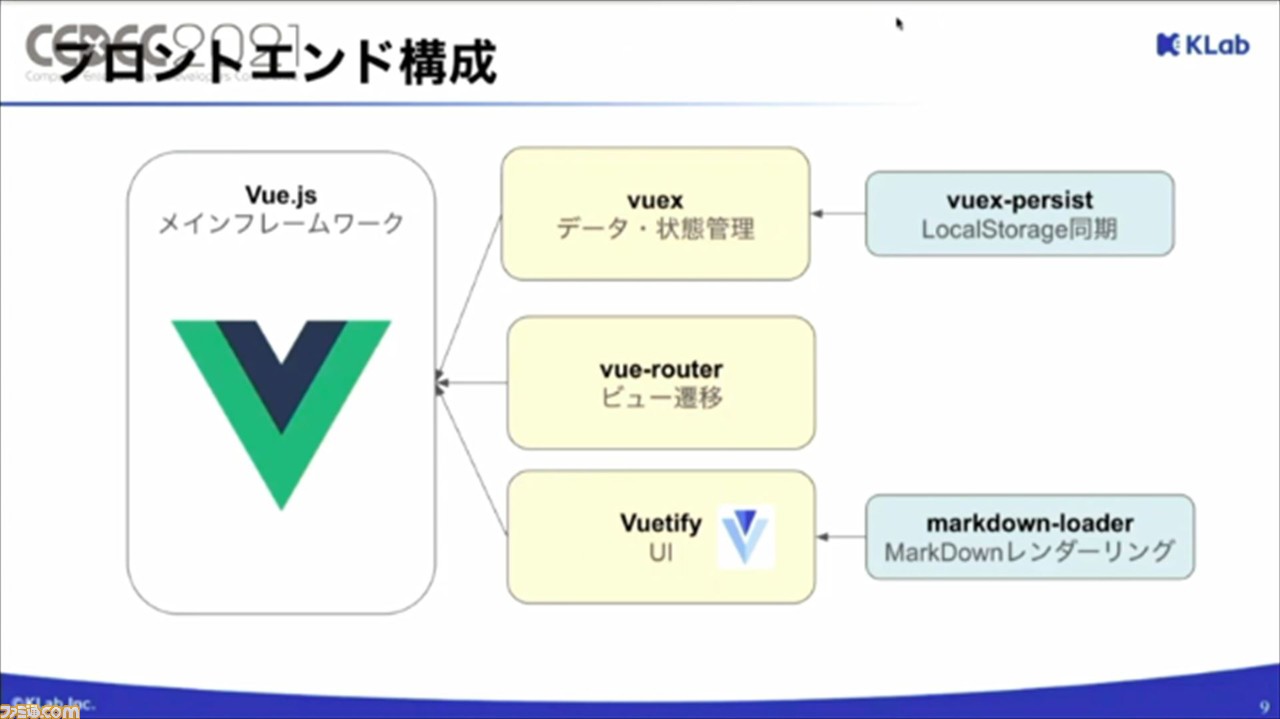
続いては、使いやすくするためのポイントについて。ツールは、ユーザーの感想や要望を取り入れながら、さまざまな工夫がなされているのだそう。
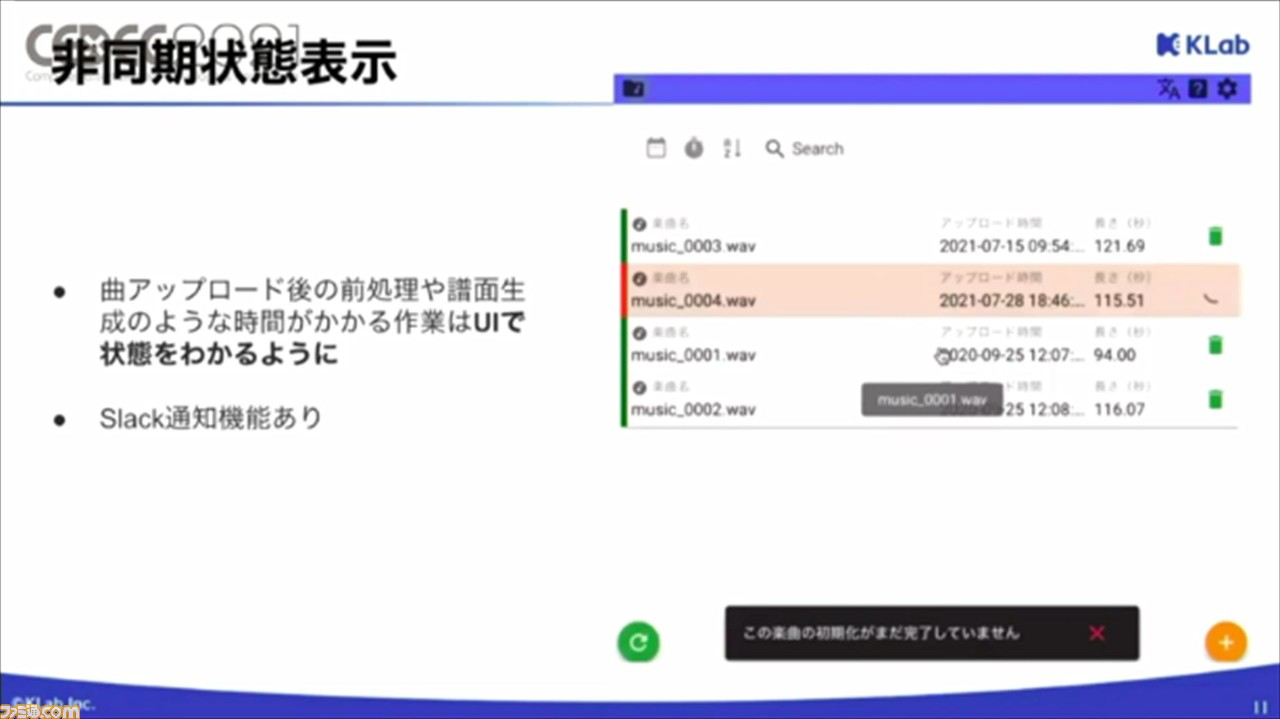
ひとつ目は、非同期状態表示。楽曲のアップロード後の前処理や譜面生成は時間がかかるため、UIで進捗状況がわかるように。Slack通知機能もあるので、時間のかかる工程でも、ストレスなく行えるようになったそうだ。
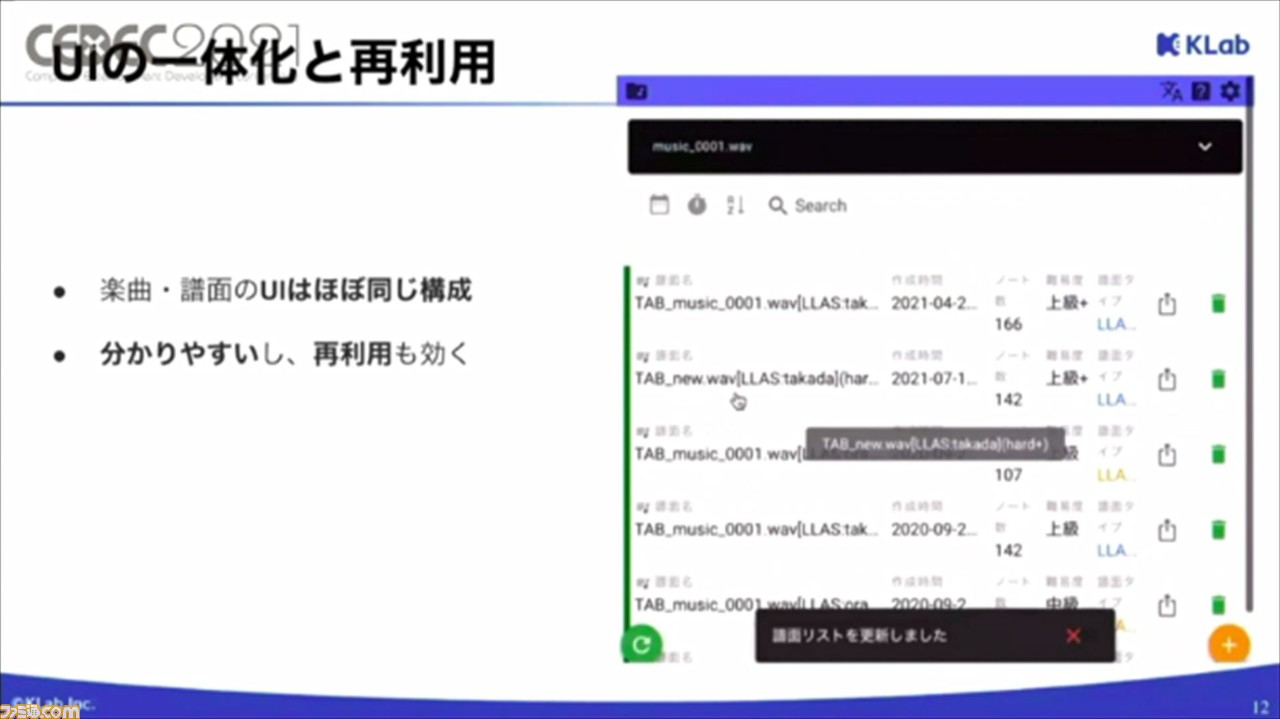
ふたつ目は、UIの一体化と再利用。楽曲・譜面のUIはほぼ同じ構成になっているそうで、UIを一体化することでユーザーがわかりやすく、再利用しやすいという利点がある。
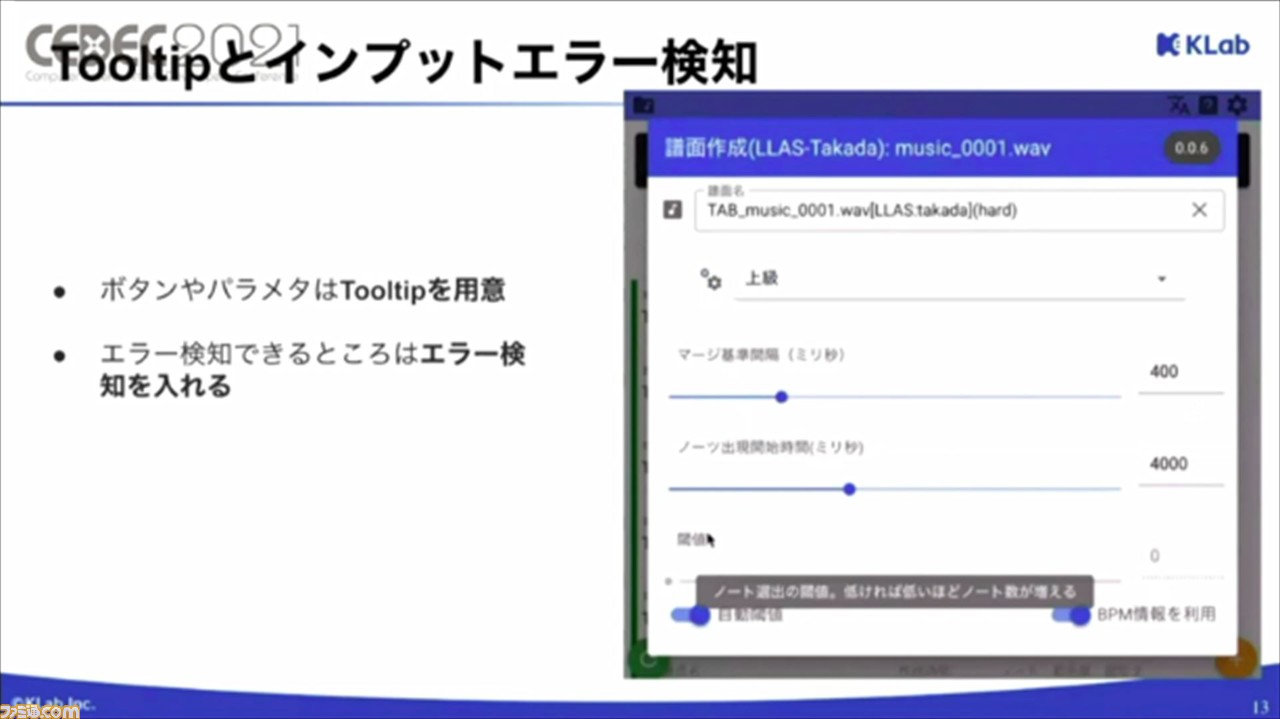
3つ目は、ツールチップとインプットエラー検知機能。ボタンやパラメータにツールチップを用意されており、カーソルを合わせることでツールチップが表示され、説明が表示される。エラー検知機能も備わっているので、どのユーザーでも使いやすいツールとなっている。
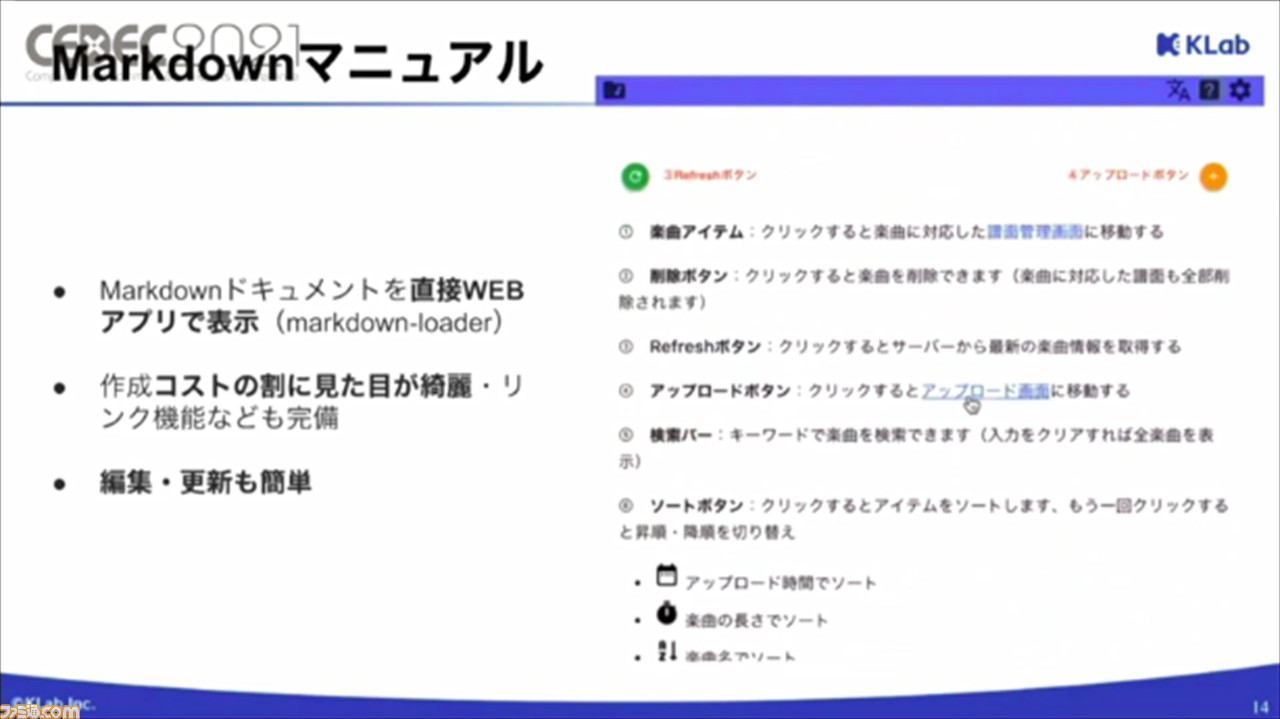
ほかにも、詳細な操作を確認できるマニュアルをMarkdownで作成し、直接WEBアプリで表示できるように。また、編集や更新も手軽に行えるという利点も。現場からも好評の声が届いているそうだ。
最後に、少人数で効率的に開発を進めるポイントについて。今回の運用システムは、フロントエンド、バックエンド、データベース、タスク管理、ユーザー認証など、一般的なWEBサービスの要素をすべて含んでいる複雑なものとなっているが、開発期間もリソースも少なくなっているのだそう。

その要因として、まずは開発環境が挙げられる。開発をきこりと例えるなら、開発環境は、きこりの持つ斧と言えるとのこと。斧の使いやすさは開発効率に関わるが、より効率的に開発を進めるために便利なのが、DockerとVisual Studio Codeの組み合わせだという。

続いては、バックエンドに関して。バックエンドは、Pythonで作成した機械学習モデルをそのまま使用したいので、APIの開発もPythonを用いているのだそう。Pythonは、性能的にはややネガティブな印象が感じられるが、非同期ベースのASGIという仕組みを利用することで、そこそこのパフォーマンスが期待できるとのこと。
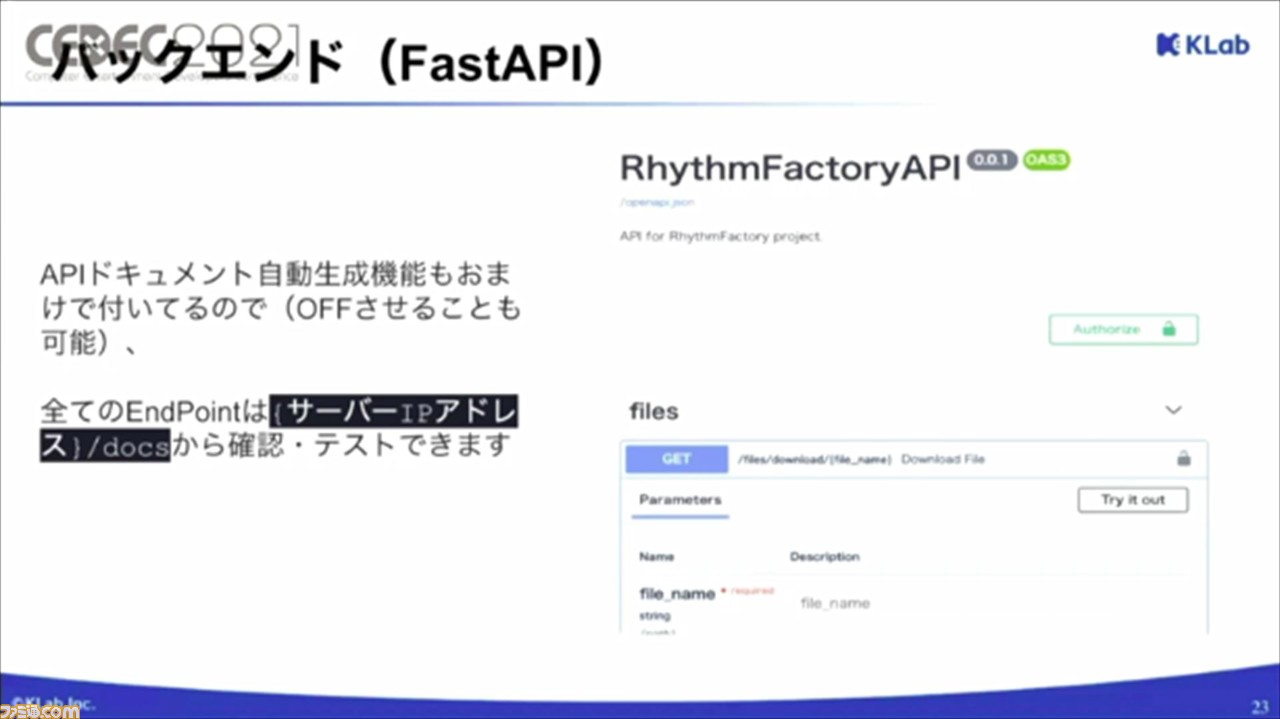
ASGIフレームワークでもっともオススメなのが、FastAPI。こちらは、著名なStarletteと呼ばれるフレームワークのラッパーのようなものだそう。FastAPIのほうがドキュメントが理解しやすく、5分でチュートリアルができるほど使いやすいのだそう。
また、APIドキュメントの自動生成機能も備わっているので、かんたんにAPIのテストができ、バックエンドの開発がより快適になるそうだ。

モデルの扱いについても、要因のひとつ。モデルは、機械学習系アプリのコアとなる部分。更新頻度が高く、複数モデルを同時採用したいケースも多いとのこと。これらの特徴に合わせて、モデルごとに独立リポジトリで開発、管理すること、共通のインターフェースを決めてあげることが、開発効率を上げるポイントとなるそう。
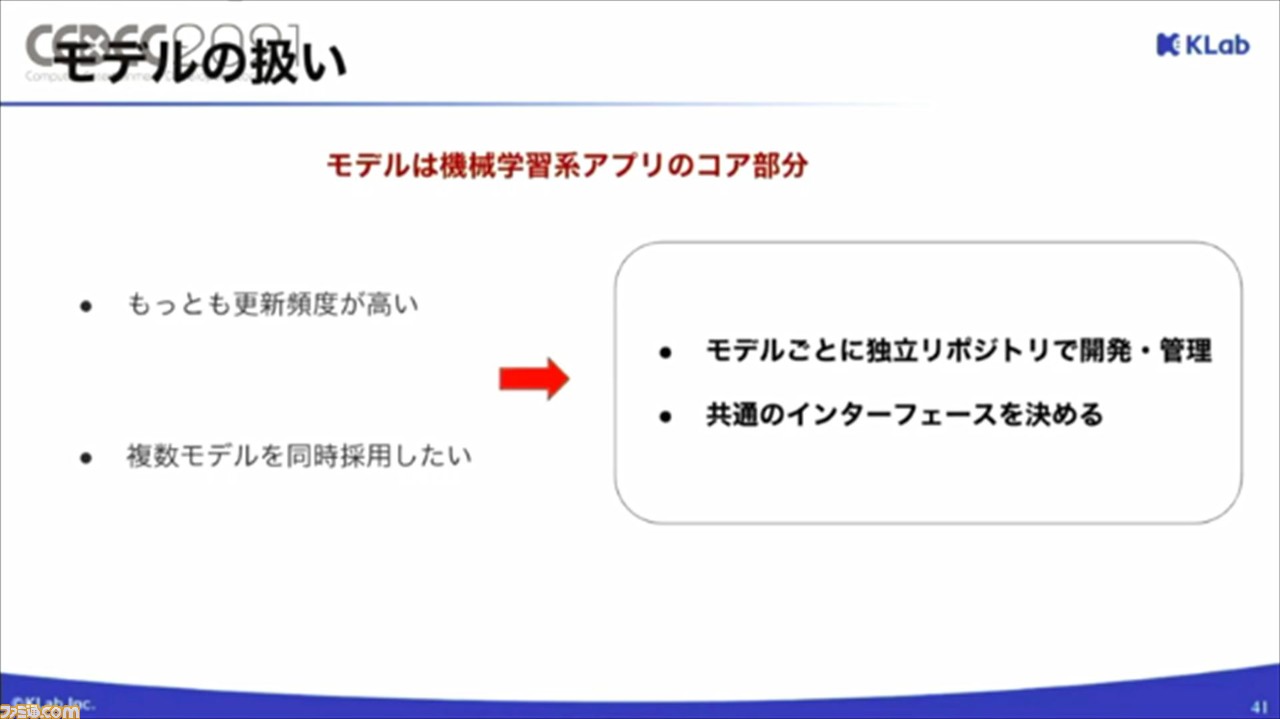
運用システムの開発においては、機械学習モデルは別チームで開発したため、応用システムとは並行して開発したそう。ただ、モデルがないと、応用システム開発において不便な場合があるため、さきにスピード重視でベースモデルを開発したとのこと。

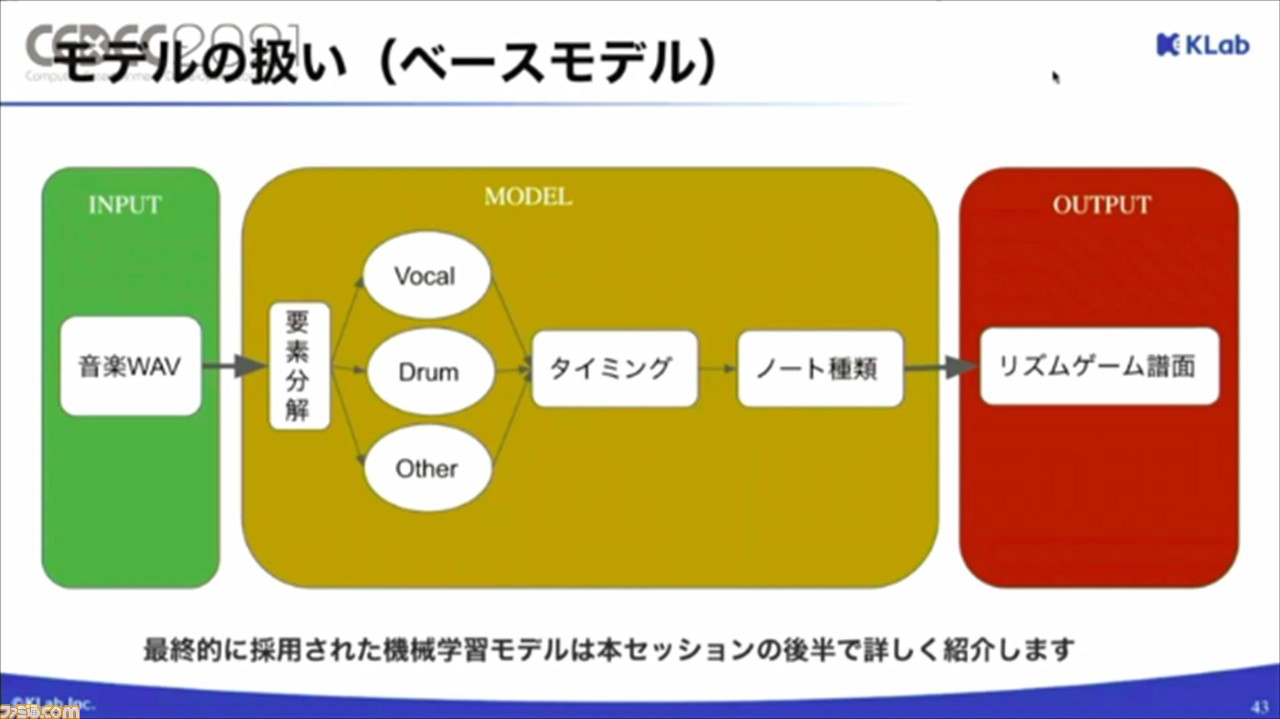
ペースモデルは、以下の図のように開発。既存モデルを使用して要素分解やタイミング情報の抽出を行い、計算コストの低いモデルを使用してノート種類を予想してかんたんな譜面を生成するモデル。精度はそこまで良くないものの、アイデア検証や運用システムの開発には十分活用できたそうだ。
要因となった最後のピースは、デプロイと更新の工夫について。WEBアプリのデメリットは、サーバーが必要で、コストがかかるという点があるそう。譜面生成の機械学習モデルは計算量も多いため、安いマシンでは時間がかかり、メモリ不足でエラーが発生してしまうという。
そこで、コストと性能を両立させるために、自動スケーリングできるKubemetesを用い、デフロイを実施したそう。

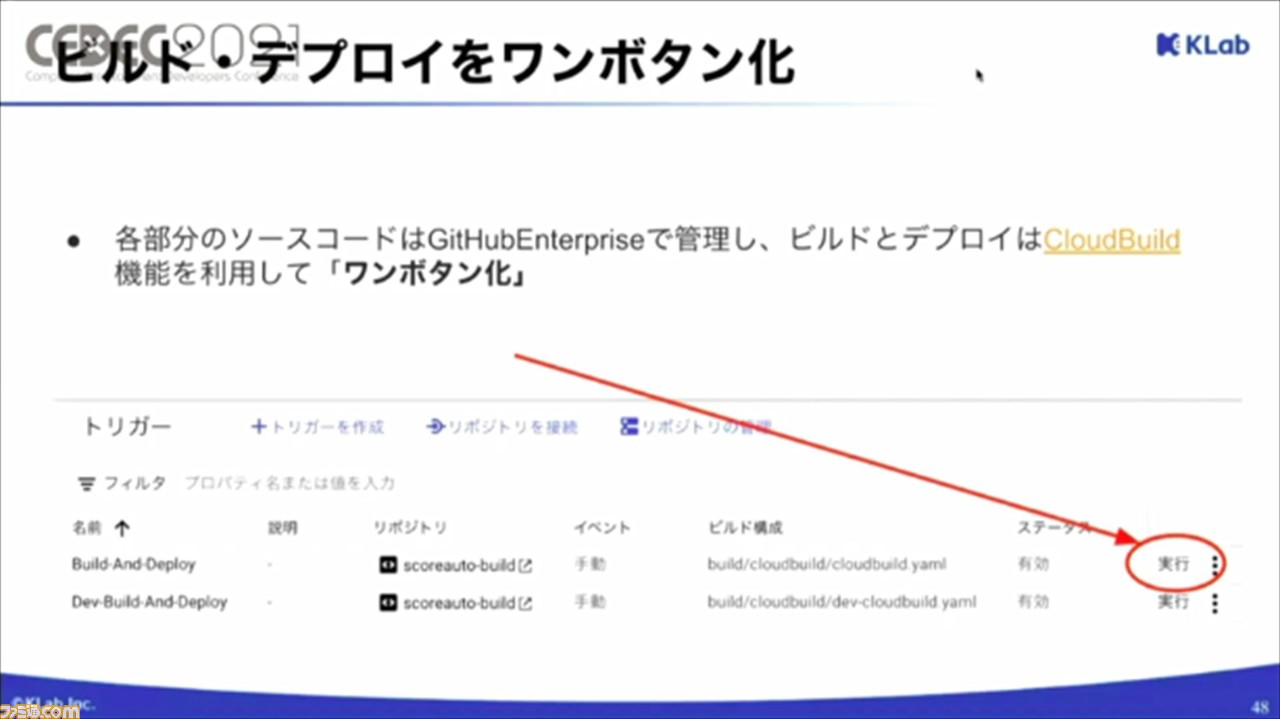
運用システムやモデルに更新が入ると、ビルドやデプロイを再度行う必要がある。このステップが多く、Kubemetesも絡むので、複雑化しやすいそう。その対策として、GitHubEnterpriseで管理されているソースコードを、CloudBuild機能を利用して、ワンボタン化。これにより、一度ビルドとデプロイの設定を行えば、以降の更新は、実行ボタンを押すだけで行えるようになるとのことだ。

ここからは、機械学習モデルについて解説。体制としては、機械学習グループが構築を担当。モデルは、既存研究をもとに独自の改良をくわえたモデルを使用し、学習用のデータは『スクスタ』のゲーム内のデータを活用しているとのこと。また、2021年3月からは、九州大学と共同研究を開始し、譜面作成支援モデルの改良を目指しているそう。


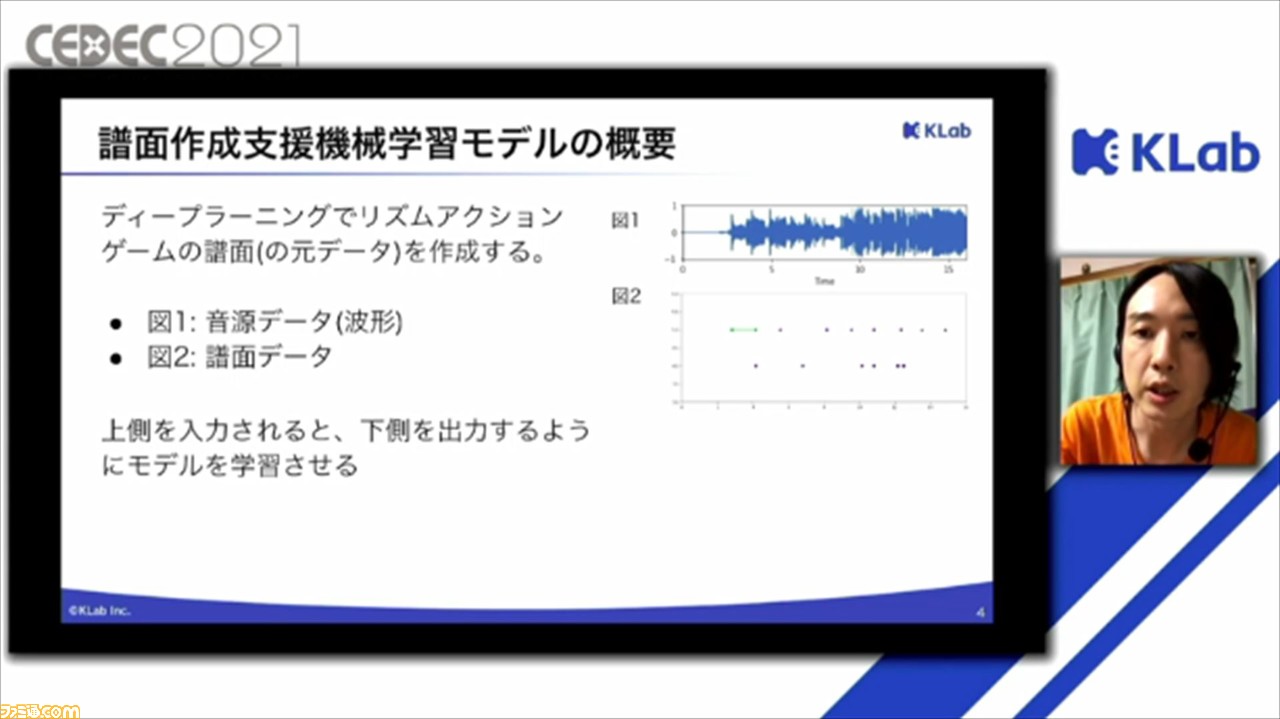
今回の機械学習モデルでやりたいことは、ディープラーニングでリズムアクションゲームの譜面を作成すること。入出力の観点では、入力となるのが音源データ、出力となるのが譜面データとなる。最終的な目標は、この入出力の流れをモデルに学習させることだそう。
先行研究では、ディープラーニングのモデルを使用して、音源から『Dance Dance Revolution』の譜面を作成する論文も発表されており、KLabでも、基本的にこの論文を参考にしているとのこと。なお、KLabでは、論文のサンプル実装とは別に、Pytorchで再実装したものを使用しているそうだ。

こちらの論文では、基本的に2種類のモデルを組み合わせることで、譜面作成が行われているという。それぞれ、Onsetモデル、Symモデルと呼ばれており、前者は、音源から時系列上でノーツがありそうな位置を推定するモデル、後者は、ノーツの種類を推定し、そこから過去のノーツのノーツ間隔をもとに、つぎのノーツの種類を決定するモデルとなっている。つまり、Onsetモデルでタイミングを決めて、Symモデルで決定したノーツ種類を当てはめていくという流れで譜面が作成されていくそうだ。

譜面作成のモデルの特徴としては、画像認識と自然言語処理の要素が組み合わさっていることが特徴的だそう。音源データの解析にはOnsetモデルが関わるところで、画像に近い連続的な値を取るデータのこと。そのため、Convolution層など、画像認識と同様の要素技術が使用されるそうだ。
譜面の推定には、Onsetモデル、Symモデル両方が関わるところで、ノーツを作るということに関しては、自然言語処理に近いような離散的な値をもったデータの順序のあるパターンが問題になるそう。それに対して、LSTM層やTransformer層など、自然言語処理と同様の要素技術が使用されるという。

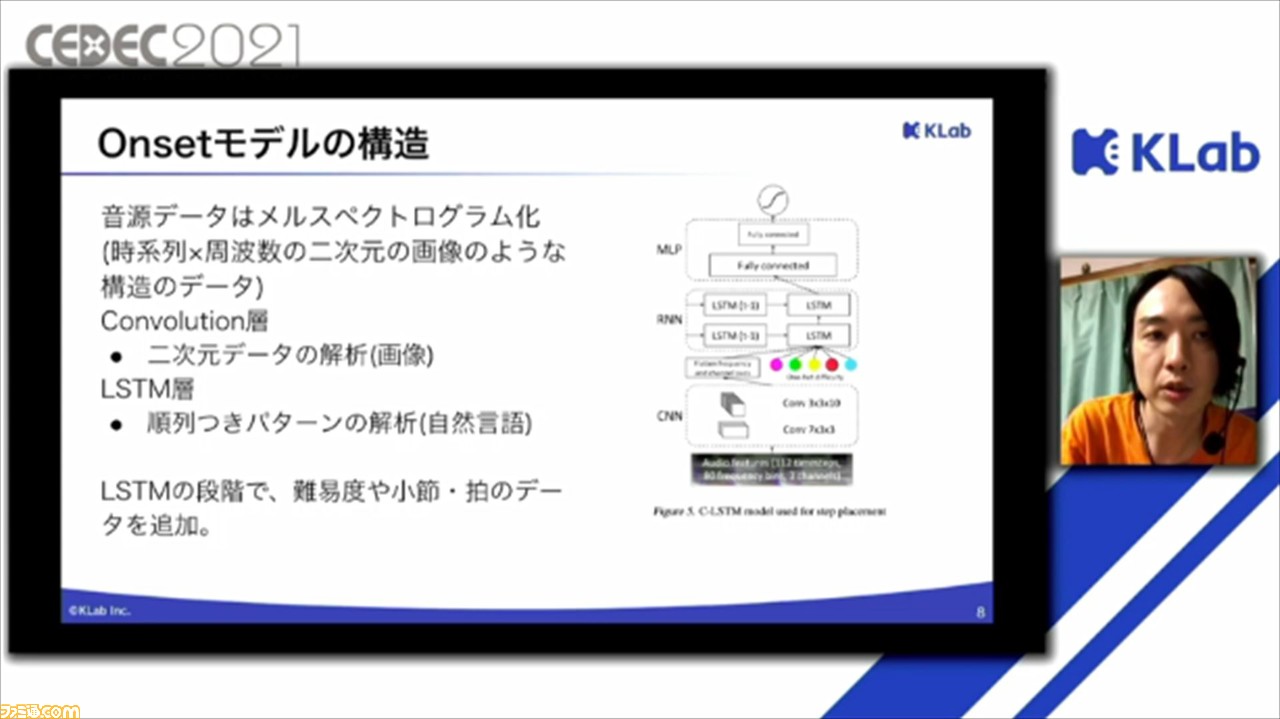
ここで、改めてOnsetモデルとSymモデルの構造について紹介された。Onsetモデルでは、音源データはメルスペクトログラムと呼ばれる二次元の画像のような構造のデータに変換したものを使用。これを、二次元データの解析に用いられるConvolution層で処理。さらに、自然言語処理で用いられるLSTM層で処理される。このLSTMの段階で、難易度や小節・拍のデータが追加されるそう。
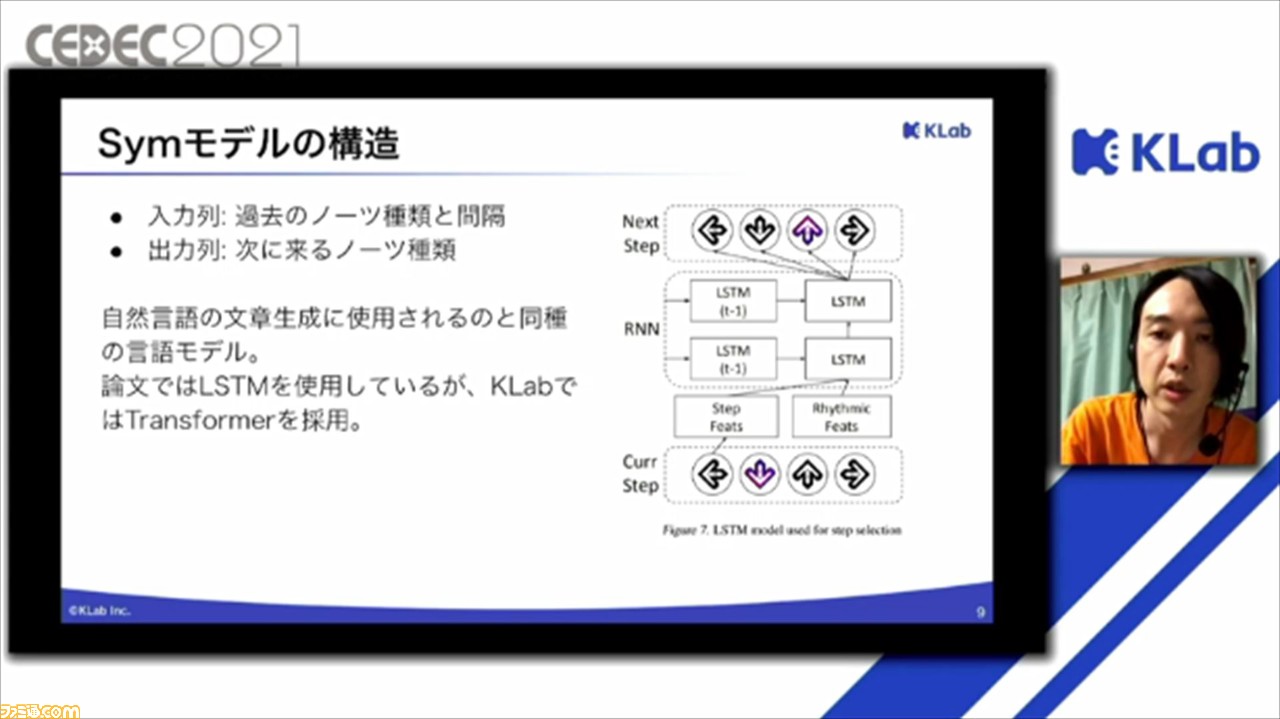
Symモデルでは、過去のノーツ種類と感覚を受け取って、つぎにくるノーツ種類を予測。このモデルは自然言語処理の文章生成に使用されるものと同じモデルを使用しているとのこと。もとの論文では、LSTMが使われていたが、KLabでは、より性能のよりTransformerを採用しているそうだ。
入力として使用するデータは、90秒程度の楽曲の音源データ100曲程度。それぞれに初級、中級、上級、上級+の難易度があり、BPMによって拍と音節の位置を追加しているそう。出力データは、ゲーム内の譜面データもとに作成しているとのこと。

BPM情報の利用は、初級、中級などの低難易度の譜面作成時に行われる。低難易度の譜面の場合、ノーツは小節や拍の位置にある場合がほとんどで、拍が何秒おきにくるかはBPMによって決定する。BPMは人間が譜面を作るときにも重要な情報なので、社内でも管理用のデータが用意されているそうだ。

セッションでは、現在検証中の試みについても紹介。それは、GAN(敵対的生成ネットワークの)と呼ばれるモデルの導入で、おもに画像生成などの領域で注目されている技術のひとつ。一般には画像生成での使用例がほとんどだが、GAN自体はモデルの学習法のテクニックなので、さまざまなデータで使用できるそう。それゆえ、リズムアクションゲームの譜面でも使用できないか検証しているとのこと。

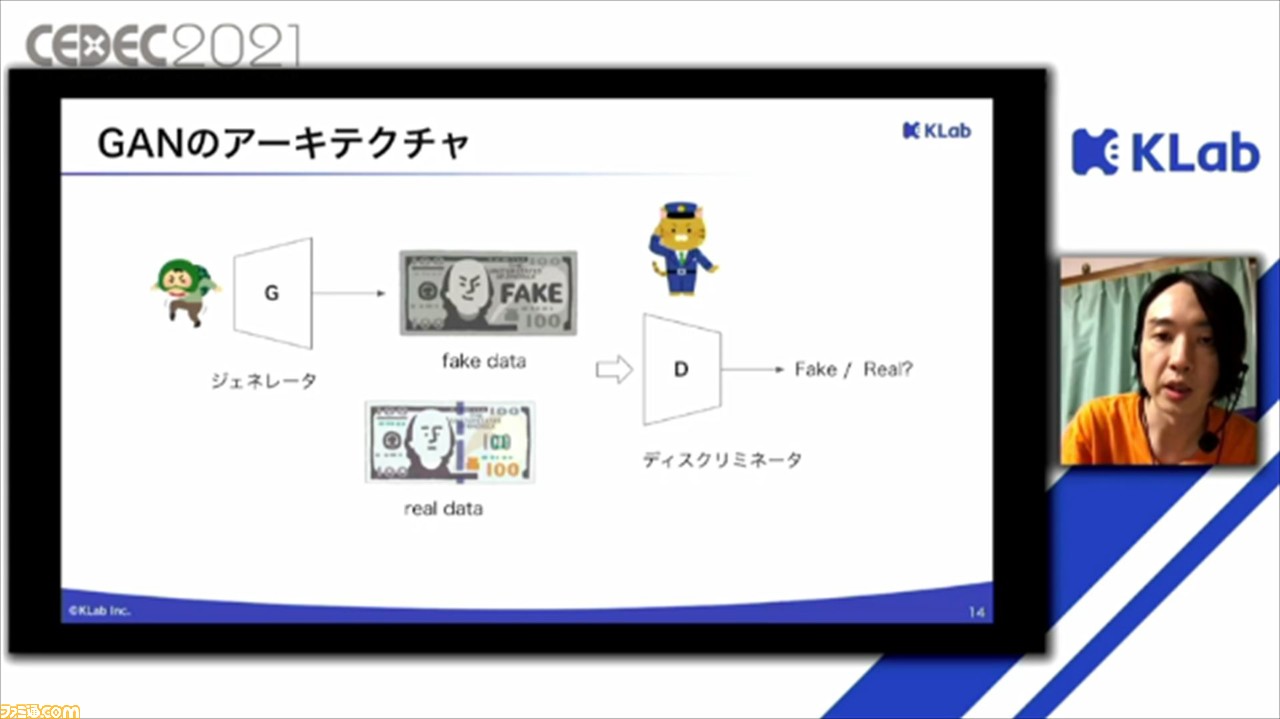
GANは、ジェネレータ、ディスクリミネータと呼ばれる2種類のモデルを交互に学習させることで、高度な偽物を作り出す技術。ジェネレータとディスクリミネータは、偽札作りと偽札を摘発する警察官に例えられることが多いそうで、ジェネレータは、リアルデータを真似てフェイクデータを作成し、ディスクリミネータを騙すことができたら成功という形で学習を行う。
一方のディスクリミネータは、フェイクデータまたはリアルデータを入力して、それがフェイクかリアルかを当てる形で学習を行う。この2種類のモデルを交互に学習させることで、ディスクリミネータはフェイクとリアルを識別する機能が発達し、ジェネレータはより高度に学習したディスクリミネータを騙すようにさらに学習するので、どんどん成功なフェイクデータが作れるようになるという。

譜面制作の場合は、ジェネレータは音源をもとに譜面データ(ノーツ位置のみ)を作成し、ディスクリミネータは人間が作ったリアルデータとジェネレータが作成した譜面を識別する。こうして、GANの訓練を行うことで、ジェネレータがディスクリミネータを騙せるようになれば、より高度な譜面作成が行えるのではないか、ということで検証を進めているとのことだ。

最後に、まとめとして今回のプロジェクトの意義が説明。現在、画像や音楽、文章などの自動コンテンツ生成は、機械学習の中では非常にホットな領域になっているとのこと。
一方で、画像、音楽、文章などのコンテンツに関しては、自由度が高く、人間のクリエイティビティがないと作ることができないのが現状だという。一応、現在でもかなり精度の高いものを作れるようにはなっているそうだが、人間が見たときに、違和感の残るものがあり、研究は進んでいるものの、ビジネスへの応用例はかなり少ないそう。
しかしながら、ゲーム素材の中には、3Dモデルやマップ、テクスチャといった、比較的自由度の少ないものもあるため、機械学習モデルで作れるのではないかと考えているそう。また、人間による修正を前提として、ベースを機械学習モデルで作成するのであれば、実用化のハードルは大きく下がるとのこと。
ゲームはコンテンツの種類や量が非常に多いので、どうしても単純作業が多くなってしまう。なので、単純作業の部分は機械学習に任せて、人間はよりクリエイティブな作業に集中できれば、機械学習を用いたコンテンツ生成の応用の可能性は広がっていくのではないか、とまとめられたところで、セッションは終了となった。


からの記事と詳細 ( 『スクスタ』譜面作成の所要時間を半分に。機械学習によるコンテンツ制作支援の事例を紹介【CEDEC2021】 - ファミ通.com )
https://ift.tt/2YlugNL
No comments:
Post a Comment